Vor zwei Jahren half »Prompt Engineering« zu besseren Ergebnissen bei KI-Tools. Heute ist der Weg ein anderer:
- Die Datei
AGENTS.md(für die meisten KI-Tools) bzw.CLAUDE.md(für Claude Code) im Projektverzeichnis fasst wichtige Projektinformationen und Coding-Anweisungen zusammen. IDEs wie Cursor bzw. CLIs wie Claude Code oder Codex berücksichtigen diese Datei bei jedem Session-Start automatisch. Damit bietet diese Datei eine großartige Möglichkeit, das Default-Verhalten von KI-Tools den eigenen Ansprüchen anzupassen. (AGENTS.mdkönnenCLAUDE.mdauf verschiedenen Ebenen gespeichert werden, um z.B. allgemeine Coding-Anweisungen mit spezifischen Projektinformationen zu kombinieren.) -
Skills ermöglichen es, Anweisungen für bestimmte Bearbeitungsschritte im Markdown-Format zu formulieren. Während
AGENTS.mdimmer berücksichtigt wird, werden Skills nur bei Bedarf ausgewertet. Skills können auch Anweisungen für den Aufruf externer Tools beinhalten und ersetzen dann in manchen Fällen die MCP-Server-Konfiguration. (Auch Skills können wahlweise projektspezifisch oder auf globaler Ebene eingerichtet werden.)
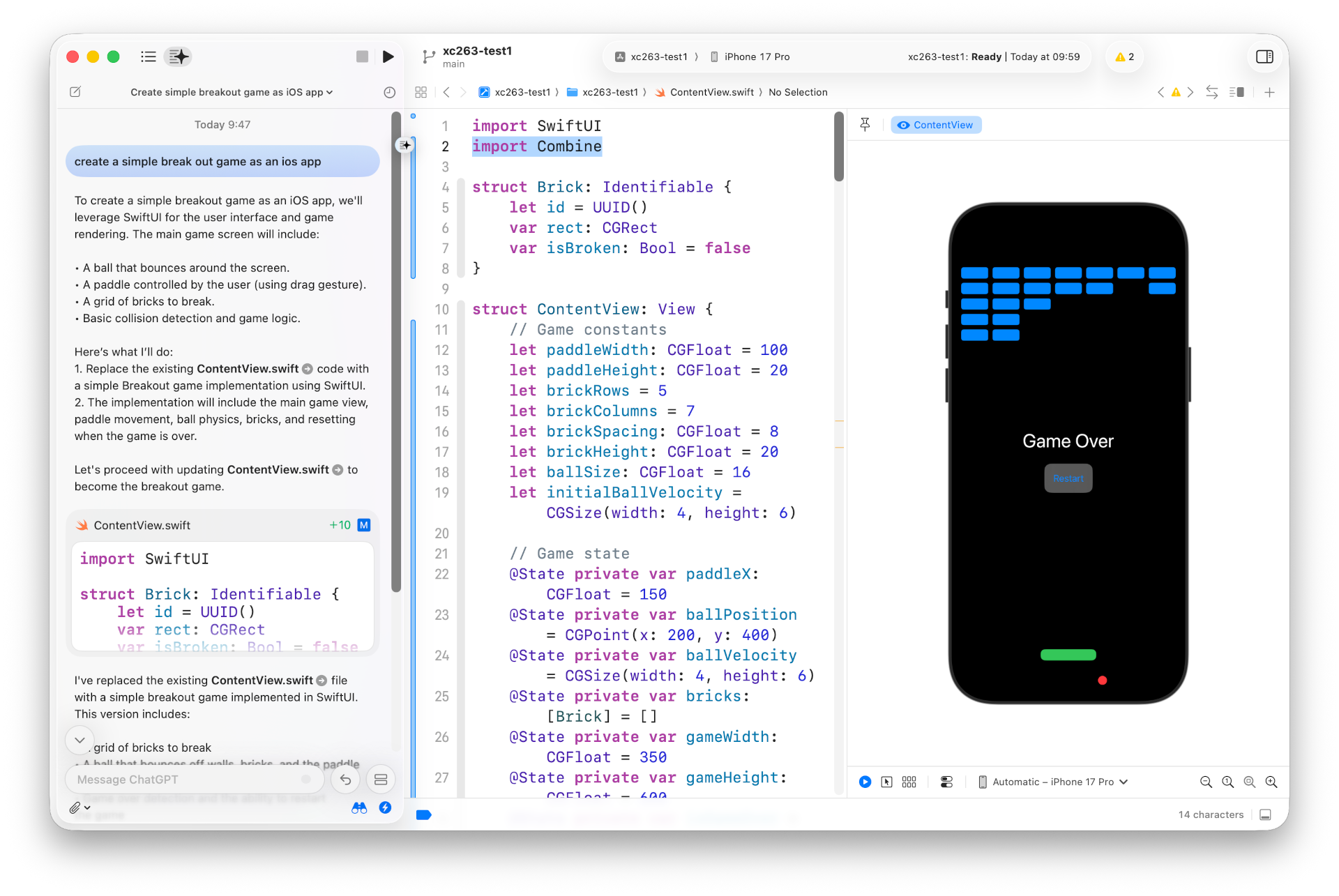
Dieser Beitrag zeigt die Anwendung von AGENTS.md und Skills speziell für die Programmiersprache Swift — losgelöst davon, ob Sie in Xcode arbeiten oder eine externe CLI verwenden. Der Artikel hat einen leichten Claude-Fokus, weil ich mich persönlich in der Anthropic-Welt wohler fühle als in der von OpenAI. Qualitativ gibt es keine großen Unterschiede zwischen beiden Systemen, beide funktionieren mittlerweile herausragend gut.
Ich setze hier voraus, dass Sie grundlegende Erfahrung mit KI-Tools haben und zumindest ein CLI-Tool (ich empfehle Claude Code, aber auch Codex CLI, Gemini CLI, Copilot CLI usw.) ausprobiert haben.